Canary Rollout of a ML Model¶
This tutorial shows how Iter8 can be used to implement a canary rollout of ML models hosted in a KServe modelmesh serving environment. In a canary rollout, inference requests that match a particular pattern, for example those that have a particular header, are directed to the candidate version of the model. The remaining requests go to the primary, or initial, version of the model. Iter8 enables a canary rollout by automatically configuring the network to distribute inference requests.
After a one time initialization step, the end user merely deploys candidate models, evaluates them, and either promotes or deletes them. Iter8 automatically handles the underlying network configuration.
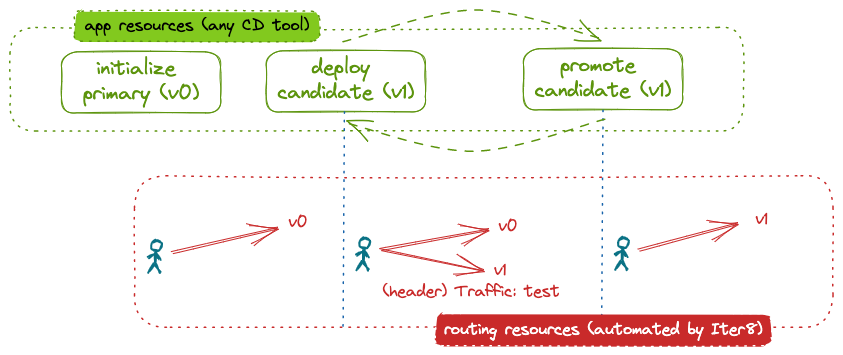
In this tutorial, we use the Istio service mesh to distribute inference requests between different versions of a model.
Before you begin
- Ensure that you have the kubectl CLI.
- Have access to a cluster running KServe ModelMesh Serving. For example, you can create a modelmesh-serving Quickstart environment.
- Install Istio. You can install the demo profile.
Install the Iter8 controller¶
Install the Iter8 controller using helm as follows.
helm install --repo https://iter8-tools.github.io/iter8 iter8-traffic traffic
Install the Iter8 controller using kustomize as follows.
kubectl apply -k 'https://github.com/iter8-tools/iter8.git/kustomize/traffic/namespaceScoped?ref=v0.14.8'
kubectl apply -k 'https://github.com/iter8-tools/iter8.git/kustomize/traffic/clusterScoped?ref=v0.14.8'
Deploy a primary model¶
Deploy the primary version of a model using an InferenceService:
cat <<EOF | kubectl apply -f -
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: wisdom-0
labels:
app.kubernetes.io/name: wisdom
app.kubernetes.io/version: v0
iter8.tools/watch: "true"
annotations:
serving.kserve.io/deploymentMode: ModelMesh
serving.kserve.io/secretKey: localMinIO
spec:
predictor:
model:
modelFormat:
name: sklearn
storageUri: s3://modelmesh-example-models/sklearn/mnist-svm.joblib
EOF
About the primary InferenceService
Naming the model with the suffix -0 (and the candidate with the suffix -1) simplifies the rollout initialization. However, any name can be specified.
The label iter8.tools/watch: "true" lets Iter8 know that it should pay attention to changes to this InferenceService.
Inspect the deployed InferenceService:
kubectl get inferenceservice wisdom-0
When the READY field becomes True, the model is fully deployed.
Initialize the Canary routing policy¶
Initialize model rollout with a canary traffic pattern as follows:
cat <<EOF | helm template traffic --repo https://iter8-tools.github.io/iter8 traffic-templates -f - | kubectl apply -f -
templateName: initialize-rollout
targetEnv: kserve-modelmesh
trafficStrategy: canary
modelName: wisdom
EOF
The initialize-rollout template (with trafficStrategy: canary) configures the Istio service mesh to route all requests to the primary version of the model (wisdom-0). Further, it defines a routing policy that will be used by Iter8 when it observes changes in the models. By default, this routing policy sends inference requests with the header traffic set to the value test to the candidate version of the model and all remaining inference requests to the primary version of the model. For detailed configuration options, see the Helm chart.
Verify network configuration¶
To verify the network configuration, you can inspect the network configuration:
kubectl get virtualservice -o yaml wisdom
To send inference requests to the model:
-
Create a "sleep" pod in the cluster from which requests can be made:
curl -s https://raw.githubusercontent.com/iter8-tools/docs/v0.14.3/samples/modelmesh-serving/sleep.sh | sh - -
exec into the sleep pod:
kubectl exec --stdin --tty "$(kubectl get pod --sort-by={metadata.creationTimestamp} -l app=sleep -o jsonpath={.items..metadata.name} | rev | cut -d' ' -f 1 | rev)" -c sleep -- /bin/sh -
Make inference requests:
or, to send a request with headercd demo cat wisdom.sh . wisdom.sh . wisdom-test.shtraffic: test:cat wisdom-test.sh . wisdom-test.sh
-
In a separate terminal, port-forward the ingress gateway:
kubectl -n istio-system port-forward svc/istio-ingressgateway 8080:80 -
Download the proto file and a sample input:
curl -sO https://raw.githubusercontent.com/iter8-tools/docs/v0.13.18/samples/modelmesh-serving/kserve.proto curl -sO https://raw.githubusercontent.com/iter8-tools/docs/v0.13.18/samples/modelmesh-serving/grpc_input.json -
Send inference requests:
or, to send a request with headercat grpc_input.json | \ grpcurl -plaintext -proto kserve.proto -d @ \ -authority wisdom.modelmesh-serving \ localhost:8080 inference.GRPCInferenceService.ModelInfertraffic: test:cat grpc_input.json | \ grpcurl -plaintext -proto kserve.proto -d @ \ -H 'traffic: test' \ -authority wisdom.modelmesh-serving \ localhost:8080 inference.GRPCInferenceService.ModelInfer
Note that the model version responding to each inference request can be determined from the modelName field of the response.
Deploy a candidate model¶
Deploy a candidate model using a second InferenceService:
cat <<EOF | kubectl apply -f -
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: wisdom-1
labels:
app.kubernetes.io/name: wisdom
app.kubernetes.io/version: v1
iter8.tools/watch: "true"
annotations:
serving.kserve.io/deploymentMode: ModelMesh
serving.kserve.io/secretKey: localMinIO
spec:
predictor:
model:
modelFormat:
name: sklearn
storageUri: s3://modelmesh-example-models/sklearn/mnist-svm.joblib
EOF
About the candidate InferenceService
The model name (wisdom) and version (v1) are recorded using the labels app.kubernets.io/name and app.kubernets.io.version.
In this tutorial, the model source (field spec.predictor.model.storageUri) is the same as for the primary version of the model. In a real example, this would be different.
Verify network configuration changes¶
The deployment of the candidate model triggers an automatic reconfiguration by Iter8. Inspect the VirtualService to see that inference requests are now distributed between the primary model and the secondary model according to a header matching rule:
kubectl get virtualservice wisdom -o yaml
Send additional inference requests as described above.
Promote the candidate model¶
Promoting the candidate involves redefining the primary InferenceService using the new model and deleting the candidate InferenceService.
Redefine the primary InferenceService¶
cat <<EOF | kubectl replace -f -
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: wisdom-0
labels:
app.kubernetes.io/name: wisdom
app.kubernetes.io/version: v1
iter8.tools/watch: "true"
annotations:
serving.kserve.io/deploymentMode: ModelMesh
serving.kserve.io/secretKey: localMinIO
spec:
predictor:
model:
modelFormat:
name: sklearn
storageUri: s3://modelmesh-example-models/sklearn/mnist-svm.joblib
EOF
What is different?
The version label (app.kubernets.io/version) was updated. In a real world example, spec.predictor.model.storageUri would also be updated.
Delete the candidate InferenceService¶
kubectl delete inferenceservice wisdom-1
Verify network configuration changes¶
Inspect the VirtualService to see that the it has been automatically reconfigured to send requests only to the primary model.
Clean up¶
Delete the candidate model:
kubectl delete --force isvc/wisdom-1
Delete routing artifacts:
cat <<EOF | helm template traffic --repo https://iter8-tools.github.io/iter8 traffic-templates -f - | kubectl delete --force -f -
templateName: initialize-rollout
targetEnv: kserve-modelmesh
trafficStrategy: canary
modelName: wisdom
EOF
Delete the primary model:
kubectl delete --force isvc/wisdom-0
Uninstall the Iter8 controller:
Delete the Iter8 controller using helm as follows.
helm delete iter8-traffic
Delete the Iter8 controller using kustomize as follows.
kubectl delete -k 'https://github.com/iter8-tools/iter8.git/kustomize/traffic/namespaceScoped?ref=v0.14.8'
kubectl delete -k 'https://github.com/iter8-tools/iter8.git/kustomize/traffic/clusterScoped?ref=v0.14.8'